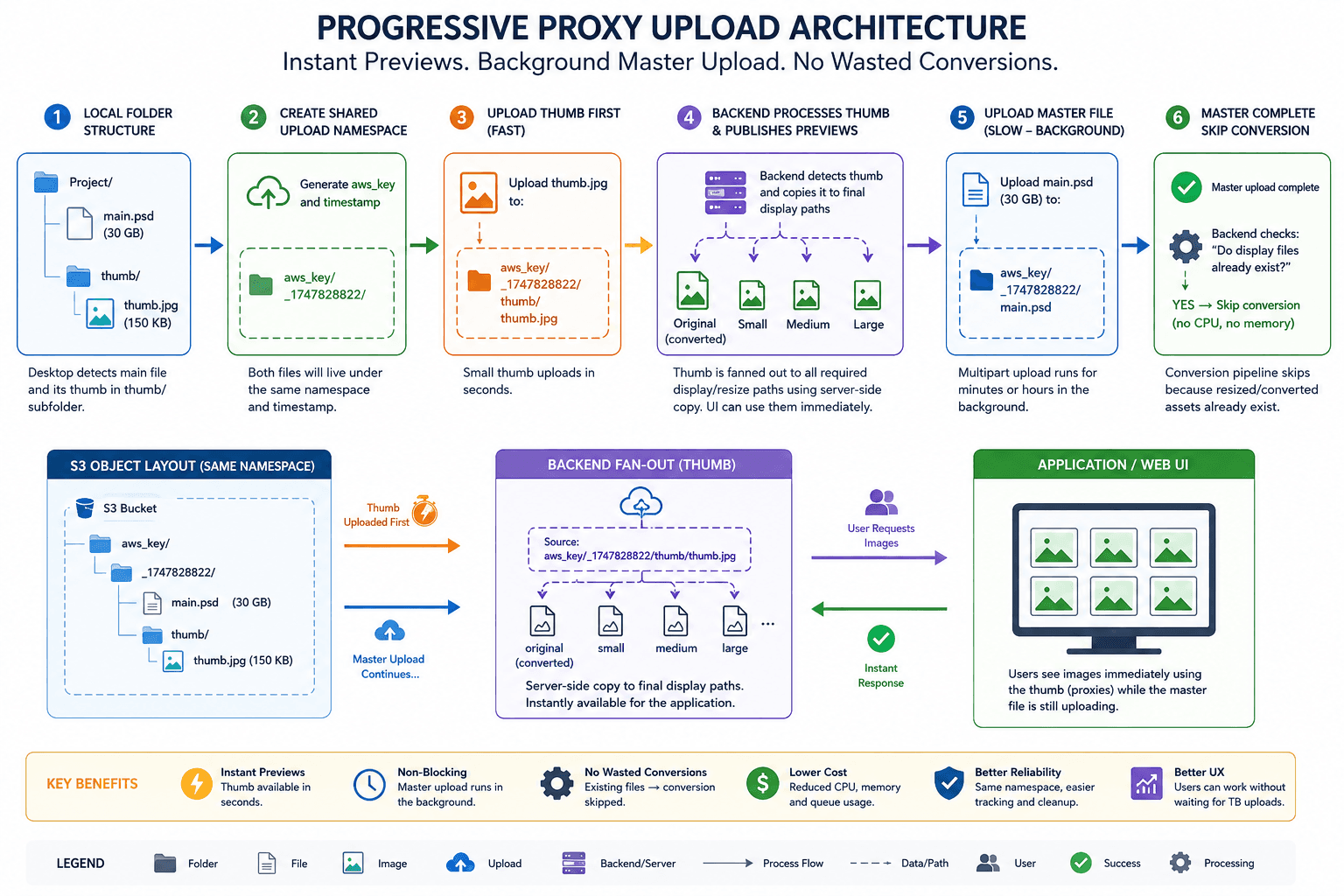
📦 Chunked File Upload Over TCP (Node.js net): Streams, Retries & Temp Storage
When you're building a desktop app that needs to upload large files (say 1GB+), sending the entire file at once is risky. Instead, split it into chunks and upload them one by one using streams.
This blog shows how to do that using Node.js's net module (TCP), how to handle stream retry issues, and how to simulate AWS S3 multipart upload behavior, with a focus on disk-based chunk storage, not in-memory.
🧩 What We’re Building
A
net-based TCP file upload serverA client that reads a file chunk by chunk via
fs.createReadStreamOn each retry, it recreates the stream
Chunks are saved temporarily on disk
Finally, chunks are merged like AWS multipart upload
⚠️ Why Not Keep Chunks in Memory?
Holding large files or many chunks in RAM = 🧨 memory bloat
Disk-based temp files simulate real-world AWS S3 multipart flow:
- Upload → Store in temporary object → Finalize (CompleteMultipartUpload)
🛠 Step 1: The TCP Upload Server
// net-upload-server.js
const net = require('net');
const fs = require('fs');
const path = require('path');
const tempDir = path.join(__dirname, 'temp');
if (!fs.existsSync(tempDir)) fs.mkdirSync(tempDir);
let chunkIndex = 0;
const server = net.createServer((socket) => {
const tempFile = path.join(tempDir, `chunk_${chunkIndex++}.part`);
const writeStream = fs.createWriteStream(tempFile);
socket.pipe(writeStream);
socket.on('end', () => console.log(`✅ Chunk saved: ${tempFile}`));
socket.on('error', (err) => console.error('❌ Socket error:', err.message));
});
server.listen(5000, () => {
console.log('📡 Server running on port 5000');
});
📤 Step 2: Client – Chunk Upload with Retry
// net-upload-client.js
const fs = require('fs');
const net = require('net');
const CHUNK_SIZE = 10 * 1024 * 1024; // 10MB
function uploadChunk(filePath, start, end, attempt = 1) {
return new Promise((resolve, reject) => {
const stream = fs.createReadStream(filePath, { start, end });
const client = net.createConnection({ port: 5000 }, () => {
stream.pipe(client);
});
client.on('end', resolve);
client.on('error', (err) => reject(err));
stream.on('error', (err) => reject(err));
});
}
async function uploadFile(filePath) {
const fileSize = fs.statSync(filePath).size;
let offset = 0;
while (offset < fileSize) {
const start = offset;
const end = Math.min(offset + CHUNK_SIZE - 1, fileSize - 1);
let retries = 3;
while (retries--) {
try {
await uploadChunk(filePath, start, end);
console.log(`✅ Chunk uploaded: ${start}-${end}`);
break;
} catch (err) {
console.error(`❌ Retry failed: ${start}-${end}`, err.message);
if (retries === 0) throw new Error('Upload failed');
await new Promise(res => setTimeout(res, 1000));
}
}
offset += CHUNK_SIZE;
}
}
🧬 Step 3: Merge Chunks Like AWS CompleteMultipartUpload
// merge.js
const fs = require('fs');
const path = require('path');
const tempDir = path.join(__dirname, 'temp');
const finalPath = path.join(__dirname, 'final_upload.bin');
const files = fs.readdirSync(tempDir)
.filter(f => f.endsWith('.part'))
.sort(); // chunk_0.part, chunk_1.part...
const writeStream = fs.createWriteStream(finalPath);
for (const file of files) {
const chunk = fs.readFileSync(path.join(tempDir, file));
writeStream.write(chunk);
}
writeStream.end(() => {
console.log(`✅ Final file merged at ${finalPath}`);
});
🔁 Retry Stream: Why It’s Crucial to Recreate It
Streams are one-time data pipelines. After they are read, errored, or ended:
They can’t be reused.
Retrying with the same stream =
"Cannot pipe. Already used"or silent failure.Always create a new stream for each retry.
✅ fs.createReadStream(file, { start, end }) inside retry loop
❌ Caching or reusing the stream across retries
🪣 AWS Multipart Upload Analogy
| AWS Step | Local net Upload Equivalent |
UploadPart | fs.createReadStream() + TCP send |
UploadPart failed | Retry with new stream |
temp object on S3 | .part file saved in temp/ |
CompleteMultipartUpload | Merge .part files into final output |
✅ Summary
Chunk large files using streams
Use Node.js
netmodule to simulate raw transportAlways retry with new readable streams
Save chunks to disk to avoid memory spikes
Merge them at the end like AWS does